
Kathmandu Class 9 Textbook Questions and Answers CBSE English Chapter 10 NCERT Beehive
KATHMANDU
(Textbook Questions)
Thinking about the Text
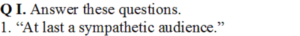
(i) Who says this?
Answer: Gerrard
(ii) Why does he say it?
Answer: Because the intruder had agreed to listen about Gerrard.
(iii) Is he sarcastic or serious?
Answer: Sarcastic


Answer: The intruder was being hunted for a long time for a crime. He was tired of running around. He wanted to live peacefully. After assuming the identity of Gerrard he would be free to roam around, eat well, sleep well and live peacefully.
Built of both were similar. So clothes of Gerrard would easily fit for intruder. Intruder could easily copy the cultured style of Gerrard. Not many people used to come to cottage so less chances of intruder getting caught. Cops were less in that area so the intruder could live peacefully in the cottage.
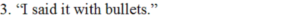
(i) Who says this?
Answer: Gerrard
(ii) What does it mean?
Answer: It means that Gerrard had murdered a person.
(iii) Is it the truth? What is the speaker’s reason for saying this?
Answer: This is not true. Gerrard wanted to divert attention of intruder. It was to dodge the intruder.

Answer: The profession of Gerrard is to supply props and other supporting equipment for plays.
We come to know about it when he informs his person that he would not be able to supply props for the play. But he would supply these for the next play.
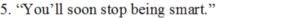
(i) Who says this?
Answer: Intruder
(ii) Why does the speaker say it?
Answer: The intruder wanted to know certain things about Gerrard. But Gerrard was not affected by the behaviour of intruder. So to frighten Gerrard, intruder said these words.
(iii) What according to the speaker will stop Gerrard from being smart?
Answer: When the intruder forces Gerrard to crawl, he would stop acting smart. Meaning that when Gerrard comes to know about intention of intruder, he might get frightened and start obeying orders.
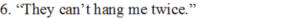
(i) Who says this?
Answer: Intruder
(ii) Why does the speaker say it?
Answer: Intruder wants to frighten Gerrard. He wanted to convince Gerrard that he would not hesitate to kill Gerrard.

Answer: These words are spoken by Gerrard. He wants to explain about the crime he had done. Why he frequently goes out of his cottage. Why he avoids meeting people. And that he was expecting some problem because of the murder done by him earlier.
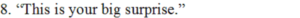
(i) Where has this been said in the play?
Answer: When intruder threatens to kill Gerrard, he says this to the intruder.
(ii) What is the surprise?
Answer: The intruder will be hanged if not as himself then as Vincent Charles Gerrard
Thinking about Language

Answer: site, ghastly
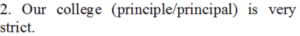 Answer: principal
Answer: principal
 Answer: continuously
Answer: continuously
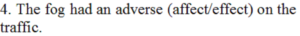 Answer: effect
Answer: effect
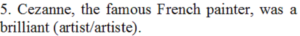 Answer: artist
Answer: artist
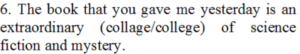 Answer: collage
Answer: collage
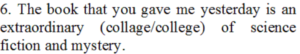 Answer: host
Answer: host
 Answer: shake
Answer: shake


| What the author say | What he means |
| Why, this is a surprise, Mr— er— | He pretends that the intruder is a social visitor whom he is welcoming. In this way he hides his fear. |
| At last a sympathetic audience! | He pretends that the intruder wants to listen to him, whereas actually the intruder wants to find out information for his own use. |
| Better be careful, wise guy! | The intruder wants to say that he knows that Gerrard owns a car. He wants Gerrard to speak the truth |
| You are much luckier. | Gerrard wants to convince the intruder that it will be good for him not to do one more murder. Actually he wants to save his own life. |
| Look for yourself. | Gerrard invites the intruder to make sure that what he is telling is truth. But actually he is making a plan to push the intruder into cupboard to save himself. |
Dictionary Use

| Noun | Adjective | Adverb | Verb | Meaning |
| sympathy | sympathetic | sympathetically | sympathise | Sharing feeling of others |
| familiarity | familiar | familiarly | familiarize | Understand or know something better |
| comfort | comfortable | comfortably | comfort | Free from pain or constraint |
| care | caring | carefully | care | Look after |
| surprise | surprised | surprisingly | surprise | A feeling caused by something unexpected |
****
0 Comments